

Maybe everyone has needed something like this in the past. You may be looking for a relevant key text in a PDF file. Or maybe you have a PDF file that is many pages long and you just want to get the texts. Today I will tell you how to do this with a simple bot in Python. Moreover, it is not more than 5 lines of code.Let's get started.
I use the Replit platform to avoid installing any packages or plugins. Let me tell you a little about replit for those who don't know. Replit is a runtime program compilation platform. You can develop a program in any programming language online here without installing any program on your computer. Such as C# ,Python, C, Javascript etc.. On this platform, you can work on a project with more than one person at the same time and share your code with other people. You can take a look here. First, I am thinking of putting the entire code here and explaining the code line by line.
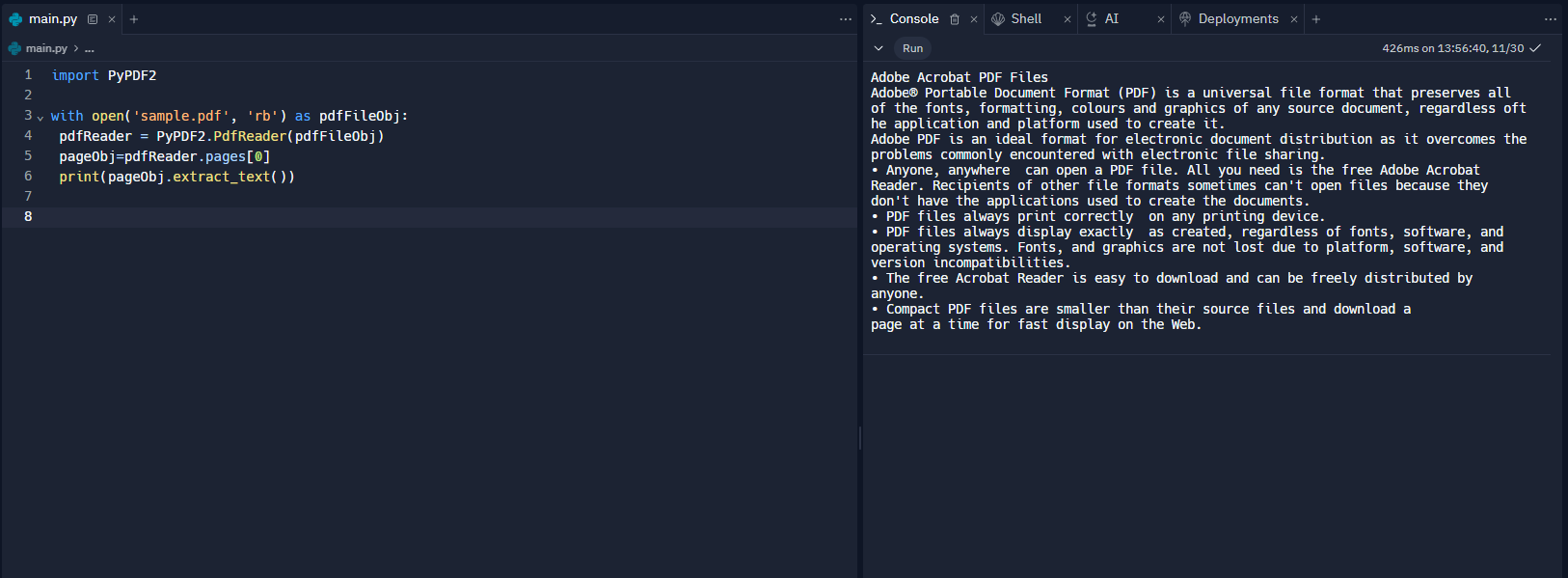
import PyPDF2
with open('sample.pdf', 'rb') as pdfFileObj:
pdfReader = PyPDF2.PdfReader(pdfFileObj)
pageObj=pdfReader.pages[0]
print(pageObj.extract_text())
In order to work with PDF documents, we include the library by importing PyPDF2. I put a sample pdf document, its name is sample.pdf. I define this document as the pdfFileObj variable. In order to read the pdf file I defined above, I create a variable called pdfReader and define it with this code pdfReader = PyPDF2.PdfReader(pdfFileObj) . There may be more than one page in your PDF file, I aim to extract only the text on the first page. I use this code for this pageObj=pdfReader.pages[0] Yes, I am printing this text that I extracted from the PDF to the screen for you to see. print(pageObj.extract_text()) .
It's that simple to make such a bot. You can develop this bot according to your needs or your imagination.For example, you have more than one PDF document and you are looking for any keyword in this PDF document.I leave the link here so that you can run the program directly and access the source codes. Here